
Tensorflow and deep learning from Pycon 2016
Самый интересный доклад + воркшоп про создание нейросети на TensorFlow от Martin Gorner из Google с конференции PyCon Russia 2016.
В качестве предметной области был датасет mnist с 50к чёрнобелых изображений цифр от 0 до 9 нарисованных от руки размером 28x28px. На вход нейросетке подаётся пачка картинок из flatten pixel mask размера 28x28=784 значения по каждой картинке, на выходе получаем вероятность класса от 0 до 9, которая сравнивается с реальным значением, функция ошибки — cross entropy.
Для задач классификации в качестве функции активации хорошо подходит softmax — возвращает число от 0 до 1, которое можно интерпретировать как вероятность класса.
Y = softmax(X * W + b)
где X — массив картинок, каждая кодируется массивом из 784 значений 1 или 0 по пикселям, W — веса каждого пиксела и b — константа (bias)
Задача нейронной сети на каждом шаге, на каждой пачке данных, подбирать оптимальные веса для каждого пикселя путём минимизации функции ошибки
cross-entropy = -sum( Y_ans_i * log(Yi) )
где Yi — предсказанное значение, Y_ans_i — реальное значение.
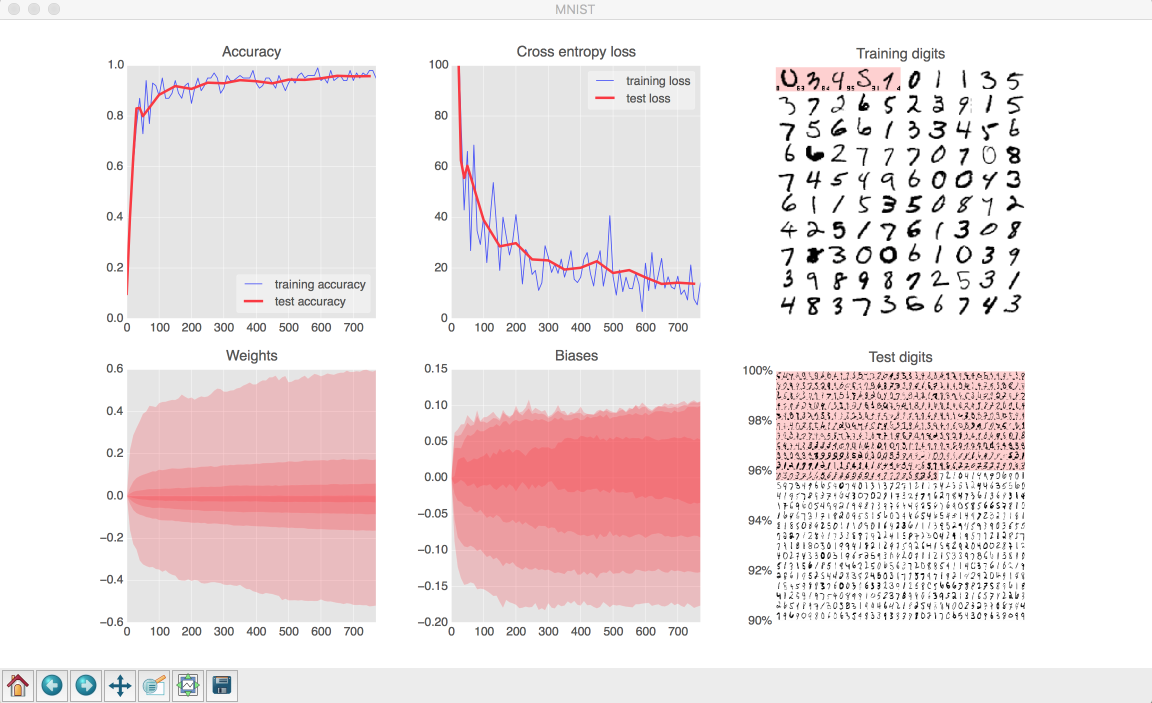
При работе с нейросетями — формируешь структуру сети, подаёшь на вход много данных и снимаешь результат. А внутри происходит магия — нейросеть сама каким-то образом выделяет закономерности. Ещё добавить к этому сложную математическую модель оптимизации, получается работа с чёрным ящиком. Поэтому разработчикам очень важно наглядно видеть результат работы. Martin написал замечательную визуализацию процесса обучения сети, где показываются графики точности, ошибки, и самих изображений цифр, на которых тестируется модель.
Базовый вариант одноуровневой нейросети с 10 нейронами выдаёт 92.6% точности. Это очень мало, если учесть, что максимальная точность предсказывания для этой задачи 99.7%. Поэтому нейронку можно и нужно улучшать и оптимизировать. Первое, что можно сделать — это создать глубокую нейросеть — добавить ещё слои. При добавлении слоёв с активацией ReLU из 200, 100, 60, 30 нейронов к базовому уровню softmax из 10 нейронов, точность возрастает до 97.2%
Следующий шаг — это регулирование learning rate decay — порога изменения весов W для нахождения минимума функции ошибки. Чем меньше значение порога — тем точнее будут подбираться веса и тем больше итераций и данных нужно, чтобы выровнялась точность предсказаний. With decaying learning rate from 0.003 to 0.0001 decay_speed 2000, 10K iterations, final test accuracy equals 0.9824.
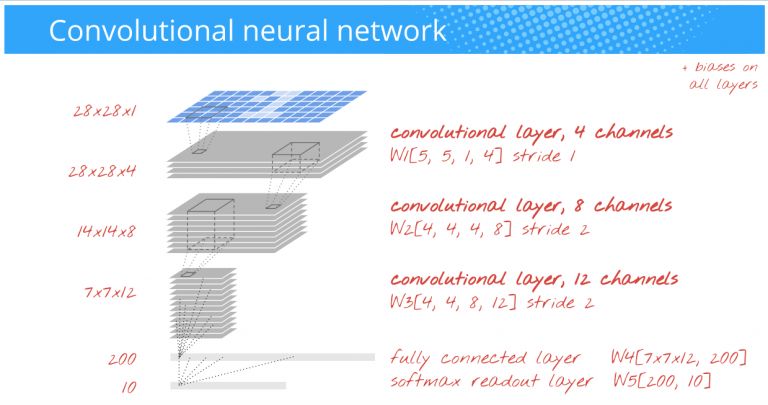
Наконец, можно использовать свёрточную (convolutional) нейронную сеть для классификации картинок. В обычной нейросети каждый нейрон связан со всеми нейронами предыдущего слоя, и каждая связь имеет свой вес. В свёрточной нейросети в операции свёртки используется небольшая матрица, «окно», которое двигается по всему слою и формирует сигнал активации для нейрона на следующем уровне с соответствующей позицией. Эта матрица (окно, ядро свёртки) построена таким образом, что графически кодирует какой-либо один признак, например, наличие наклонной линии под определенным углом. Тогда следующий слой, получившийся в результате операции свёртки матрицы весов, показывает наличие данной наклонной линии в обрабатываемом слое и её координаты, формируя карту признаков (feature map)
Так, добавив 3 свёрточных слоя (6x6str1 5x5str2 4x4str2) к полносвязному слою relu из 200 нейронов и softmax 10, получим точность 99.2%
Презентация — http://goo.gl/pHeXe7, код демки — https://github.com/martin-gorner/tensorflow-mnist-tutorial
Интервью на хабре с Мартином https://habrahabr.ru/company/it_people/blog/303832/ В нём он рассказывает про TFlearn — высокоуровневая надстройка над TensorFlow с синтаксическим сахаром для создания моделей, которую планируется внедрить в ядро TF, а пока что можно пользоваться отдельным контрибом.